We should be cautious about associations of patient characteristics with COVID-19 outcomes that are identified in hospitalised patients
Among successful actors, being physically attractive is inversely related to being a good actor. Among American college students, being academically gifted is inversely related to being good at sport.
Among people who have had a heart attack, smokers have better subsequent health than non-smokers. And among low birthweight infants, those whose mothers smoked during pregnancy are less likely to die than those whose mothers did not smoke.
These relationships are not likely to reflect cause and effect in the general population: smoking during pregnancy does not improve the health of low birthweight infants. Instead, they arise from a phenomenon called ‘selection bias’, or ‘collider bias’.
Understanding selection bias
Selection bias occurs when two characteristics influence whether a person is included in a group for which we analyse data. Suppose that two characteristics (for example, physical attractiveness and acting talent) are unrelated in the population but that each causes selection into the group (for example, people who have a successful Hollywood acting career). Among individuals with a successful acting career we will usually find that physical attractiveness will be negatively associated with acting talent: individuals who are more physically attractive will be less talented actors (Figure 1). Selection bias arises if we try to infer a cause-effect relationship between these two characteristics in the selected group. The term ‘collider bias’ refers to the two arrows indicating cause and effect that ‘collide’ at the effect (being a successful actor).
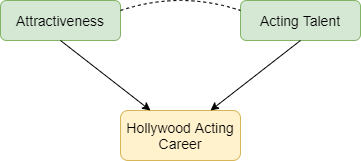
Figure 1: Selection effects exerted on successful Hollywood actors. Green boxes highlight characteristics that influence selection. Yellow boxes indicate the variable selected upon. Arrows indicate causal relationships: the dotted line indicates a non-causal induced relationship that arises because of selection bias.
Figure 2 below explains this phenomenon. Each point represents a hypothetical person, with their level of physical attractiveness plotted against their level of acting talent. In the general population (all data points) an individual’s attractiveness tells us nothing about their acting ability – the two characteristics are unrelated. The red data points represent successful Hollywood actors, who tend to be more physically attractive and to be more talented actors. The blue data points represent other people in the population. Among successful actors the two characteristics are strongly negatively associated (green line), solely because of the selection process. The direction of the bias (whether it is towards a positive or negative association) depends on the direction of the selection processes. If they act in the same direction (both positive or both negative) the bias will usually be towards a negative association. If they act in opposite directions the bias will usually be towards a positive association.
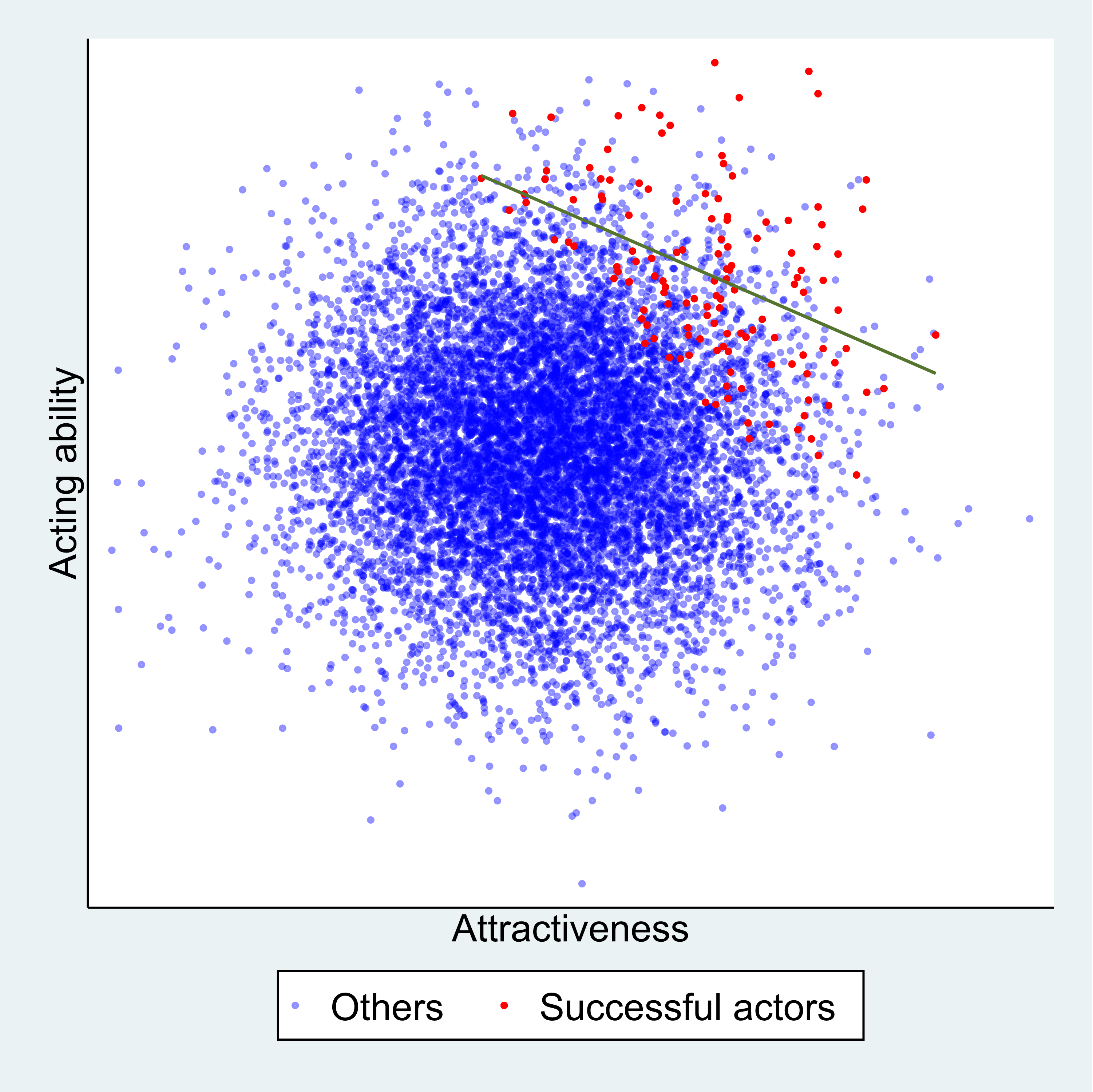
Figure 2: The effect of sample selection on the relationship between attractiveness and acting talent. The green line depicts the negative association seen in successful actors.
Why is selection bias important for COVID-19 research?
In health research, selection processes may be less well understood, and we are often unable to observe the unselected group. For example, many studies of COVID-19 have been restricted to hospitalised patients, because it was not possible to identify all symptomatic patients, and testing was not widely available in the early phase of the pandemic. Selection bias can seriously distort relationships of risk factors for hospitalisation with COVID-19 outcomes such as requiring invasive ventilation, or mortality.
Figure 3 shows how selection bias can distort risk factor associations in hospitalised patients. We want to know the causal effect of smoking on risk of death due to COVID-19, and the data available to us is on patients hospitalised with COVID-19. Associations between all pairs of factors that influence hospitalisation will be distorted in hospitalised patients. For example, if smoking and frailty each make an individual more likely to be hospitalised with COVID-19 (either because they influence infection with SARS-CoV-2 or because they influence COVID-19 disease severity), then their association in hospitalised patients will usually be more negative than in the whole population. Unless we control for all causes of hospitalisation, our estimate of the effect of any individual risk factor on COVID-19 mortality will be biased. For example, it would be unsurprising that within hospitalised patients with COVID-19 we observe that smokers have better health than non-smokers because they are likely to be younger and less frail, and therefore less likely to die after hospitalisation. But that finding may not reflect a protective effect of smoking on COVID-19 mortality in the whole population.
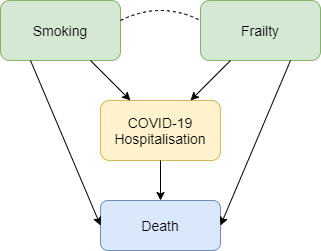
Figure 3: Selection effects on hospitalisation with COVID-19. Box colours are as in Figure 1. Blue boxes represent outcomes. Arrows indicate causal relationships, the dotted line indicates a non-causal induced relationship that arises because of selection bias.
Selection bias may also be a problem in studies based on data from participants who volunteer to download and use COVID-19 symptom reporting apps. People with COVID-19 symptoms are more likely to use the app, and so are people with other characteristics (younger people, people who own a smartphone, and those to whom the app is promoted on social media). Risk factor associations within app users may therefore not generalise to the wider population.
What can be done?
Findings from COVID-19 studies conducted in selected groups should be interpreted with great caution unless selection bias has been explicitly addressed. Two ways to do so are readily available. The preferred approach uses representative data collection for the whole population to weight the sample and adjust for the selection bias. In absence of data on the whole population, researchers should conduct sensitivity analyses that adjust their findings based on a range of assumptions about the selection effects. A series of resources providing further reading, and tools allowing researchers to investigate plausible selection effects are provided below.
The authors of this blog are Gareth J Griffith, Gibran Hemani, Annie Herbert, Giulia Mancano, Tim Morris, Lindsey Pike, Gemma C Sharp, Matt Tudball, Kate Tilling and Jonathan A C Sterne, together with the authors of a preprint on collider bias in COVID-19 studies, accessible at https://www.medrxiv.org/content/10.1101/2020.05.04.20090506v3. All authors are members of the MRC Integrative Epidemiology Unit at the University of Bristol. Jonathan Sterne is Director of Health Data Research UK South West
For further information please contact Gareth Griffith (g.griffith@bristol.ac.uk) or Jonathan Sterne (jonathan.sterne@bristol.ac.uk).
Further reading and selection tools:
Dahabreh IJ and Kent DM. Index Event Bias as an Explanation for the Paradoxes of Recurrence Risk Research. JAMA 2011; 305(8): 822-823.
Griffith, Gareth, Tim M. Morris, Matt Tudball, Annie Herbert, Giulia Mancano, Lindsey Pike, Gemma C. Sharp, Jonathan Sterne, Tom M. Palmer, George Davey Smith, Kate Tilling, Luisa Zuccolo, Neil M. Davies, and Gibran Hemani. Collider Bias undermines our understanding of COVID-19 disease risk and severity. Interactive App 2020 http://apps.mrcieu.ac.uk/ascrtain/
Groenwold, RH, Palmer TM and Tilling K. Conditioning on a mediator to adjust for unmeasured confounding OSF Preprint 2020: https://osf.io/vrcuf/
Hernán MA, Hernández-Díaz S and Robins JM. A structural approach to selection bias. Epidemiology 2004; 15: 615-625.
Munafo MR, Tilling K, Taylor AE, Evans DM and Davey Smith G. Collider Scope: When Selection Bias Can Substantially Influence Observed Associations. International Journal of Epidemiology 2018; 47: 226-35.
Luque-Fernandez MA, Schomaker M, Redondo-Sanchez D, Sanchez Perez MJ, Vaidya A and Schnitzer ME. Educational Note: Paradoxical collider effect in the analysis of non-communicable disease epidemiological data: a reproducible illustration and web application International Journal of Epidemiology 2019; 48: 640-653. Interactive App: https://watzilei.com/shiny/collider/
Smith LH and VanderWeele TJ. Bounding bias due to selection. Epidemiology 2019; 30: 509-516. Interactive App: https://selection-bias.herokuapp.com

